The rise and fall of Fable
June 15, 2026 | View Comments
How I Learned to Stop Worrying and Love the Drama
Anthropic released its splendid but nerfed Fable, causing shock and outrage in the community, then famously retracted the model after the US government decided that perhaps such a marvellous feat was too much of a good thing for those without a US passport. Access was yanked not only from mere mortals across the world, but evidently also from some of the undeserving non-US untermenschen belonging to the mythical Anthropic family itself, including a co-founder and another storied and illustrious recent hire:
Several key Anthropic personnel, including co-founder Chris Olah, AI researcher Andrej Karpathy and philosopher Amanda Askell, were born outside the United States. Reuters was unable to determine their citizenship status, and an Anthropic spokesperson declined to comment on whether such staff would lose AI model access. (source)
(Sorry for the slightly over-the-top introduction but now at least you can rest assured that this blog hasn't been written by a machine, but instead is a real fabulous stream of thoughts flowing directly from yours truly's neurons through his rather nervous system down to the fingertips and onto his keyboard.)
Developers will surely tell stories about the now stalled Fable to their grandchildren, stories that may sound like fairy tales, were it not for the actual and observed capabilities of the model, which is, among many other things, able to generate astonishingly detailed 3D representations of fantasy worlds, or of real passenger airplanes for that matter, or can be used to quickly create fun-looking games, like a cute and visually stunning goldfish feeding simulator from a single prompt, but also some really nice animated infographics and so on.

(source)
But luckily and surely it's not the end of frontier large language models for the general (non-US) public yet. The other United States AI giant's GPT-5.5 model and its successors may arguably soon fall under the same types of restrictions as did Anthropic's model. Or perhaps more likely, OpenAI's mightiest models might never make it onto the public stage like Fable did. As of today however, GPT-5.5 and its capabilities match those of Mythos/Fable in many areas and remain to be understood and leveraged by the wider community.
And while the same forces that are now trying to put a lid on open scientific progress have been convincing us that the strong and open LLMs coming out of China are undeserving or somehow a danger to our freedom (even if self-hosted?), it's reassuring to observe that some of the PRC's big AI players are, in reaction to recent news, doubling down on openness, evidently following the Chinese mentality of building bridges rather than fortresses (or military bases) for themselves, like in Africa:
"To get rich, build roads first." The popular Chinese proverb rings true in Africa. Drawing on its own development experience, China has been dedicated to working with Africa to build transport facilities crucial for economic development.
According to the white paper, "China and Africa in the New Era: A Partnership of Equals," Chinese companies over the last quarter century have helped African countries build or upgrade more than 10,000 km of railways, nearly 100,000 km of highways, roughly 1,000 bridges, almost 100 ports and 66,000 km of power transmission and distribution.
Additionally, Chinese companies have helped build an installed power-generating capacity of 120 million kW, a communications backbone network of 150,000 km and a network service covering nearly 700 million user terminals.
(source)
And perhaps that's the better mental model for open AI too: shared models, papers, benchmarks, and tooling are roads and bridges, and the side that keeps building them may end up less isolated than the one hiding inside the fortress.
What's more, there's new work that suggests that synthesising the results of multiple frontier models can outperform any individual best frontier model, making Mythos' capabilities seem less breakthrough than advertised.
Long-horizon tasks: don't get lost!
Now what makes a lot of the cool demos that we saw coming out of Fable and other frontier models work is related to LLM models' ability to handle so-called long-horizon tasks. Here's from Z.ai's GLM-5.1 release announcement from April this year:
Previous models—including GLM-5—tend to exhaust their repertoire early: they apply familiar techniques for quick initial gains, then plateau. Giving them more time doesn't help.
GLM-5.1, by contrast, is built to stay effective on agentic tasks over much longer horizons. We've found that the model handles ambiguous problems with better judgment and stays productive over longer sessions. It breaks complex problems down, runs experiments, reads results, and identifies blockers with real precision. By revisiting its reasoning and revising its strategy through repeated iteration, GLM-5.1 sustains optimization over hundreds of rounds and thousands of tool calls. The longer it runs, the better the result.
We demonstrate this across three tasks with progressively less structured feedback: a vector search optimization problem scored by a single numeric metric, a GPU kernel benchmark with per-problem speedup measurements, and an open-ended web application build where there is no metric at all—only the model's own judgment of what to improve next.
Now regardless of how well your LLM sticks to the task and can drive things forward at a high level, limited context windows and context rot are still very much a thing, and so there needs to be a way to break down long-horizon tasks to make them manageable in the first place. That's why techniques around harness engineering (think subagents, ralph loops, autoresearch) are as important as raw model capability here, because no LLM is able to do everything a long-horizon task requires in a single run and with a single context window: do research, plan, write automated tests and implementation, do Q&A, and iterate over the whole, within a single agent context.
And while a lot of serious engineers still like to stay in control of planning and organisation of tasks that they then hand out to their clankers, then later meticulously review and refine the results before merging, that pattern probably still remains important for a while to come for any serious larger software project (except Claude Code). But a different pattern seems to be emerging. For certain classes of problems that are maybe more isolated, and that can be well-defined up-front, or that have very clear success criteria, such as web apps but also GPU kernel optimisation, some of the best results can be achieved through relatively hands-off LLM orchestration and looping.
Subagents that do not suck
Now at the heart of having long-running LLM sessions that work towards a long-horizon goal are subagents, first introduced in the context of coding harnesses by Claude Code. The idea is simple: your agent gets a subagent(prompt, ...) tool, which it can provide prompts to and call to perform subtasks, giving your coding agent a convenient way to delegate tasks out to workers with either fresh or forked context, meaning the context windows of those start more or less from scratch using the instructions given, or, they start off with a copy of the parent's context window, plus some instructions on top, respectively. The benefit in the context of long-horizon tasks is obvious: The top-level or parent agent can stay on top of planning and execution, while subagents can do the dirty work of grepping code, searching the web, writing spikes, and so on. From a context-window perspective, the parent agent only has to construct high-level prompts and maintain the plan; it receives summaries or the essentials of what was done from the subagents.
Now consider what that looks like in practice in the context of building a relatively ambitious "falling blocks" clone in Zig, which I created using a single shot, or a single prompt, this weekend. This game that you can play in your browser here, was created using the Pi coding agent and a new Pi subagent extension that I created called pi-submarine, and using only the following prompt:
I want you to build a ### clone, using ~/co/raylib and specifically ~/co/raylib-zig/ I want your ### clone to be technically advanced to the point where it could be used for tournaments: think FPS, T-spins, perfect clears, and combos. Divide your work up into logical units and delegate to subagents for researching ~/co/raylib/ and ~/co/raylib-zig/ Then create a plan with phases. Then delegate each phase to a "fresh context" subagent, with useful quality gates. Make sure every subagent uses our best practices, and that they are able to actually test their results and do quality engineering as well, before they hand off. After each handoff, send a subagent to review the code, and look for simplification opportunities, before you hand over to the next subagent with "fresh context" to work on the next phase. Do not stop until you are done and satisfied with the implementation. Make sure you delegate and give agency and useful context to subagents such that they can work efficiently and you keep the overview of the project without losing focus.
Below you can see an overview of how the orchestrator split up the tasks into phases and subagents that work on them, leading to an 80-minute wall time for implementation. At the end of the implementation the orchestrator had only used some 18% of its context window (of 272k tokens).
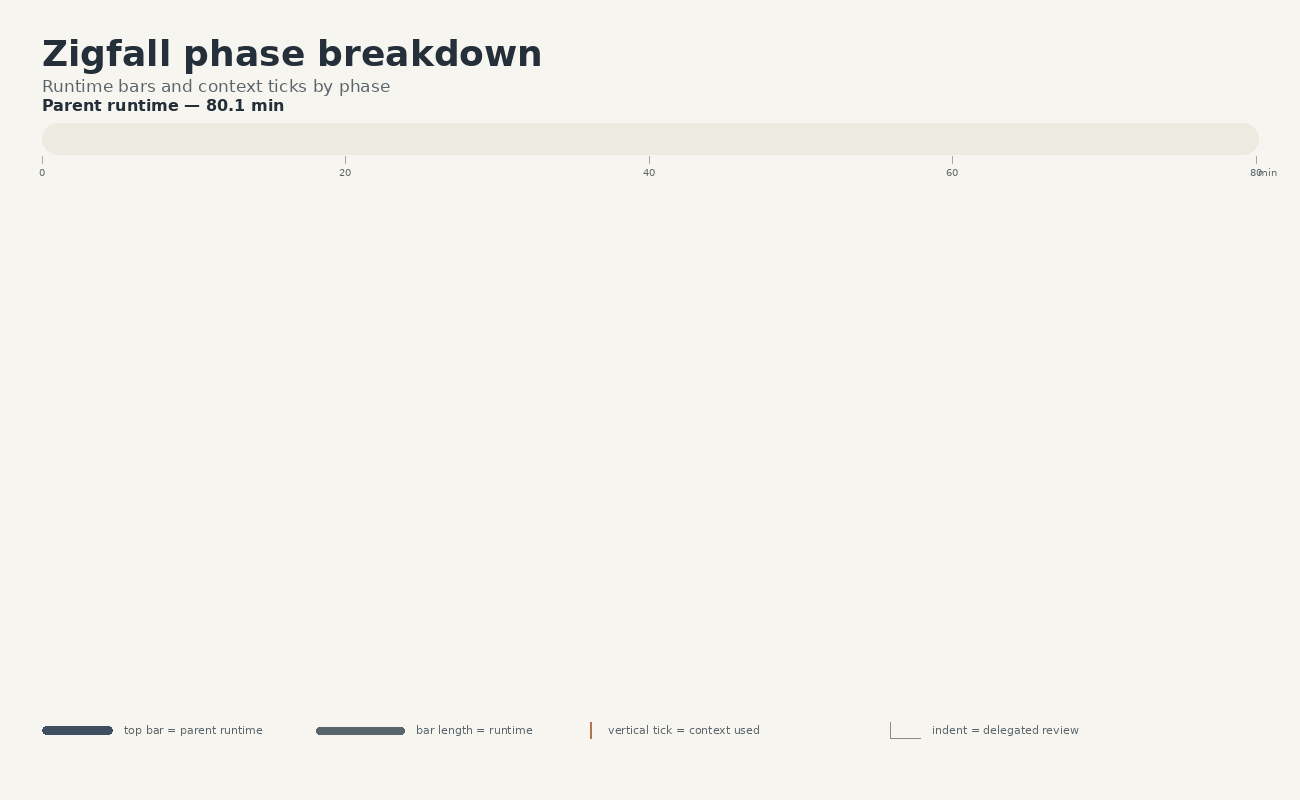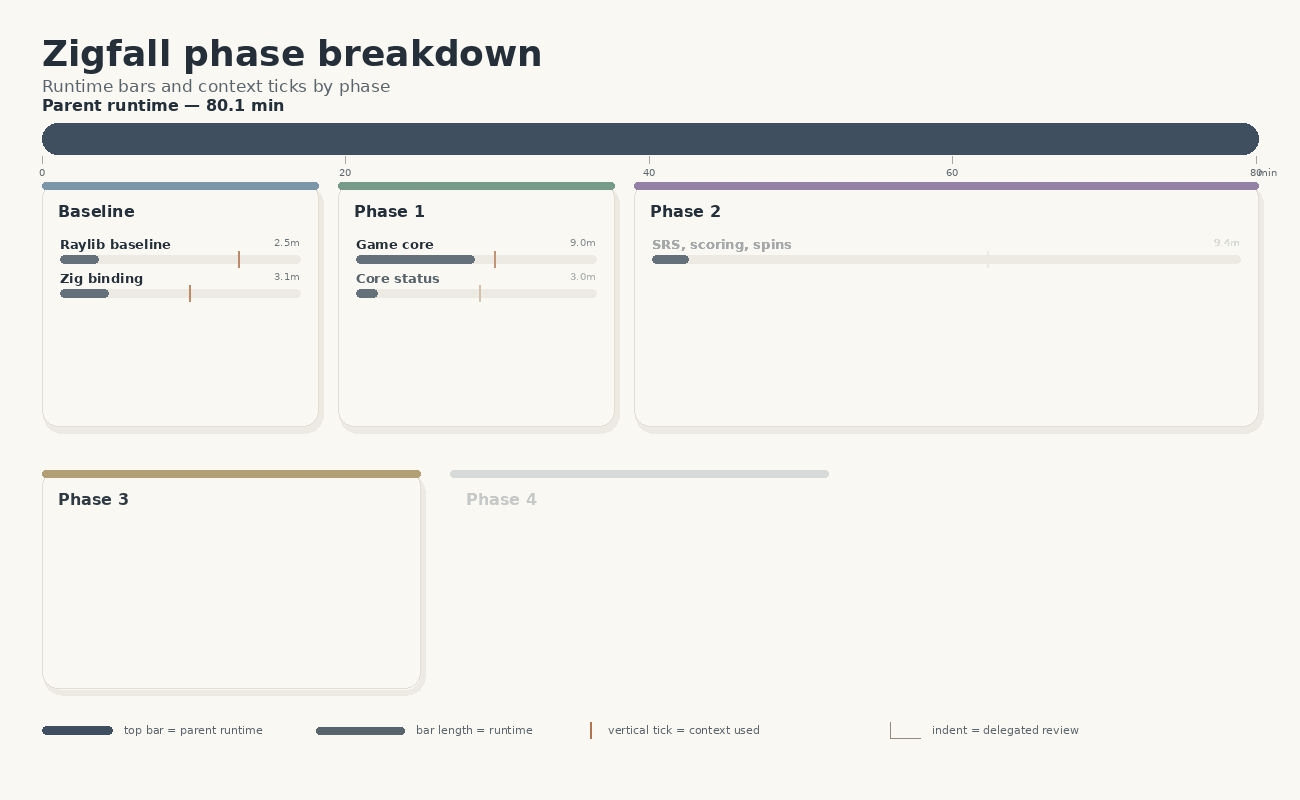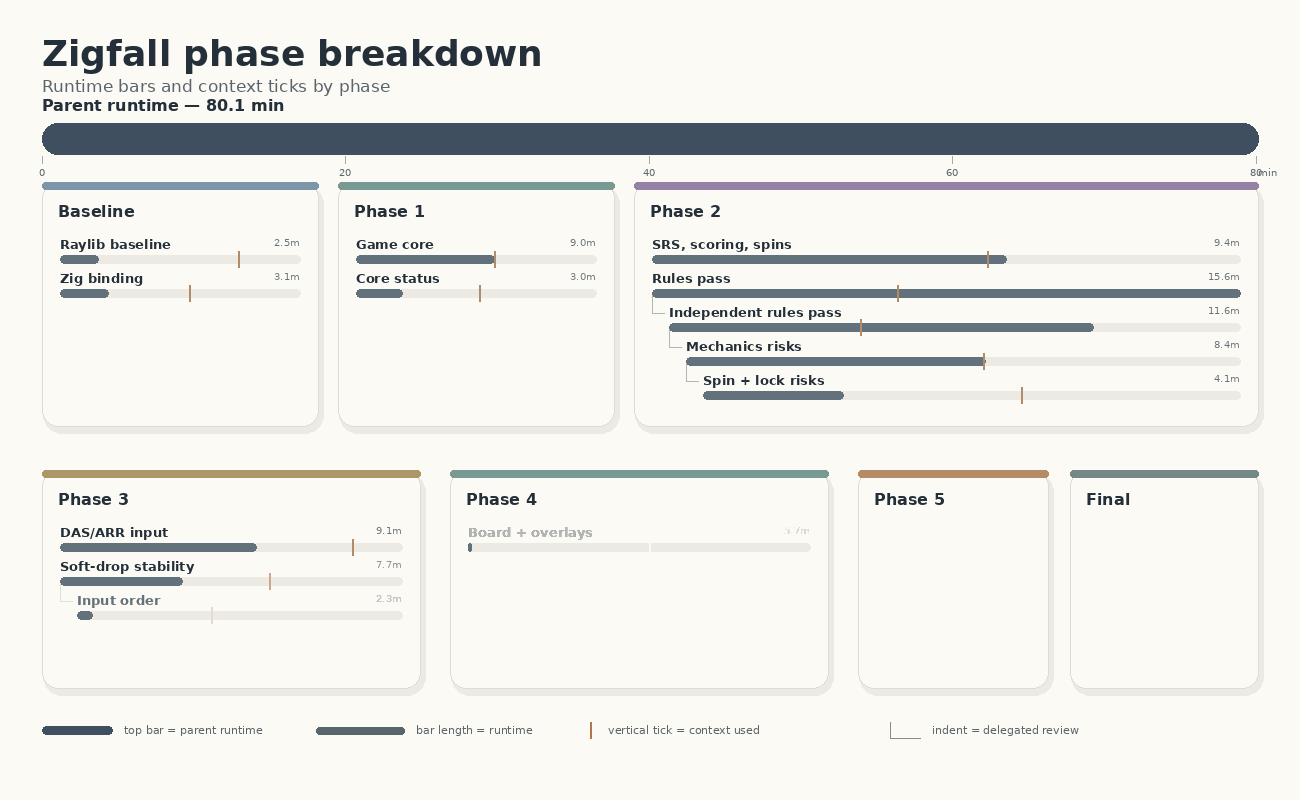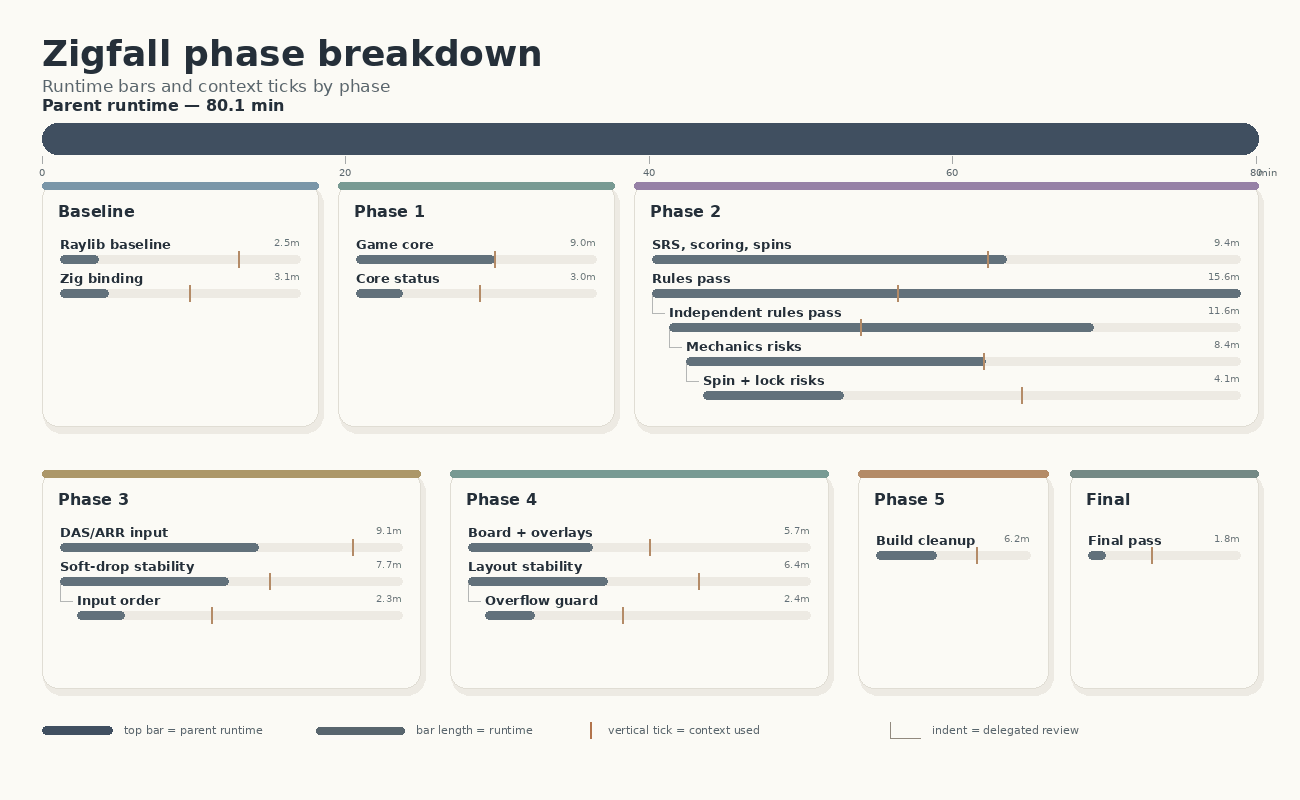
| Work item | Kind | Runtime | Context tokens | Context % | Note |
|---|---|---|---|---|---|
| Parent agent | orchestration | 80.1m | ~48,895 | ~18.0% | Overall run wrapper |
| raylib research | research | 2.5m | 60,597 | 22.3% | API/build reconnaissance |
| raylib-zig research | research | 3.1m | 43,948 | 16.2% | Dependency/import pattern |
| Phase 1 implementation | implementation | 9.0m | 46,958 | 17.3% | Scaffold and core |
| Phase 1 review | review | 3.0m | 41,958 | 15.4% | Core review |
| Phase 2 implementation | implementation | 9.4m | 46,513 | 17.1% | SRS, scoring, spins |
| Phase 2 main review | review | 15.6m | 34,001 | 12.5% | Longest subagent |
| Nested Phase 2 review | review | 11.6m | 27,361 | 10.1% | Rules audit |
| Deeper Phase 2 audit | review | 8.4m | 43,804 | 16.1% | Mechanics audit |
| Final Phase 2 audit | review | 4.1m | 48,326 | 17.8% | Risk ranking |
| Phase 3 implementation | implementation | 9.1m | 69,916 | 25.7% | Highest context usage |
| Phase 3 review/fix | review | 7.7m | 49,998 | 18.4% | Input/order fixes |
| Nested Phase 3 review | review | 2.3m | 33,705 | 12.4% | Input-order review |
| Phase 4 rendering polish | implementation | 5.7m | 43,369 | 15.9% | UI/rendering |
| Phase 4 review/fix | review | 6.4m | 54,934 | 20.2% | Layout/overlay fixes |
| Nested Phase 4 UI review | review | 2.4m | 34,621 | 12.7% | UI review |
| Phase 5 hardening | hardening | 6.2m | 53,142 | 19.5% | Docs/build cleanup |
| Final validation | validation | 1.8m | 34,141 | 12.6% | Final checks |
Now the game may seem relatively humble when compared with demos we've seen coming from Fable, but my impression is it plays very well and looks solid. It also implements some rather advanced features, and aims to be tournament grade, although, as I am not a very good player myself, I haven't been able to verify whether features like T-spin full/mini detection are implemented correctly.
Here's a two-minute recording, showing the Pi session within the Emacs frontend for Pi that generated the game, and a bit of browser gameplay:
The Pi coding agent famously does not ship a subagent implementation itself. Instead, Pi promotes its /tree command, which allows users to navigate to previous points in the chat history while summarising what happened between that point and now, allowing for an efficient alternative to managing context bloat, one of the main issues that subagents also try to solve, but perhaps in a less magical way. However, Pi also has a large library of contributed extensions, the most popular of which is a subagent extension called pi-subagents (and there are others too), which implements Claude Code-style subagents for Pi.
So far so good. Though it turns out that in the age of vibe coding, features are cheap and thus programmers get tempted to ship what's called in German an egg-laying wool-milk-sow, i.e. software that suffers from acute featuritis (hello Claude Code!), in many cases with not-so-hidden costs of complexity and lack of predictability in use.
So how is pi-submarine different, you ask? By aiming to be more minimal, perhaps following the UNIX philosophy of doing one thing, or maybe a few things, and doing them well:
- Support for "fresh" and "fork" context
- Support for named agents which are defined by markdown files with only a few configuration knobs
- Support for listing available global or per-project named agents, defined by markdown files
- Support for displaying runtime status in terms of context usage and activity
- Support for tailing an activity log
- Support for nested subagents
- Support for resuming subagent runs, if the parent agent deems it useful, perhaps because the subagent was aborted or it's errored out
That's it. There are no built-in agent definitions (I have no use for your idea of a scout agent, or your particular workflow), and no parallelism (Pi can call multiple tools in parallel these days, so support for parallel subagents comes for free). There are no fancy widgets or control panes, but an easy way to tail the activity log of all of a session's subagent calls, and a path to opening up the subagent session files in a separate Pi session for precise observability.